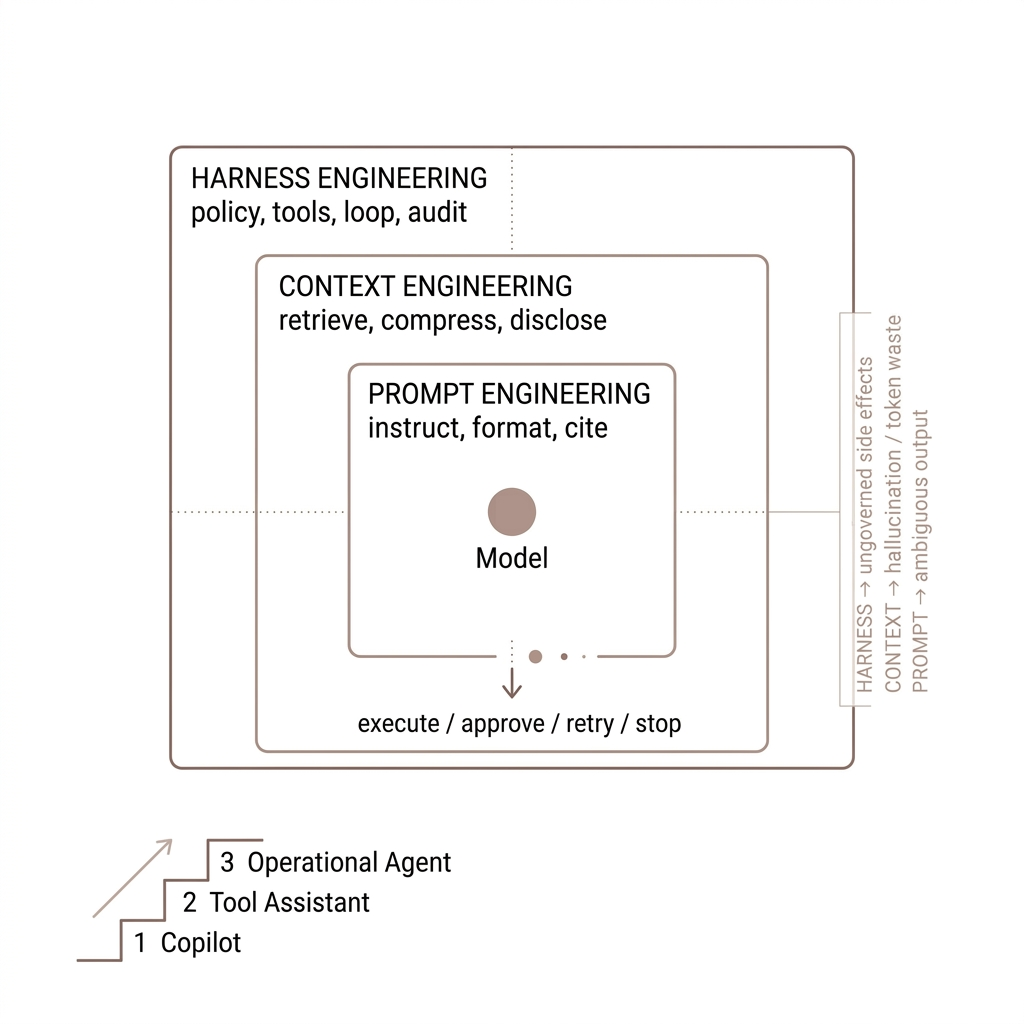
Three layers, one system
In 2023, "prompt engineering" was often treated as the whole job: find the magic system message, add a few examples, ship. As agents gained tools, memory, and side effects, failures moved elsewhere. Models hallucinated because the service catalog was missing, not because an adjective was wrong. They burned budgets because every turn resent a megabyte of instructions. They took destructive actions because nothing in the runtime said no.
Three terms now describe complementary work—each solves a different class of failure:
- Prompt engineering — shape behavior through instructions and examples in the message you send right now.
- Context engineering — decide what facts, history, and tool output land in the finite context window before the model reasons.
- Harness engineering — build the runtime around the model: tool loops, retries, policy, observability, and human gates so probabilistic output becomes dependable software.
Confusing them leads to expensive mistakes: polishing prose while the agent still cannot see ownership data, or stuffing more tokens into the window while nothing verifies tool results before a production change runs.
Prompt engineering: the ask
Prompt engineering is the craft of instructing the model clearly: role, constraints, output format, tone, and when to refuse. Few-shot examples, chain-of-thought nudges, and structured outputs (JSON schema, tool-choice hints) all live here. It matters. Ambiguous asks produce ambiguous actions.
It also has a ceiling. Prompts cannot invent facts that were never retrieved. They cannot undo a tool that returns stale JSON. They cannot substitute for an approval workflow when the blast radius is a customer database. Prompt engineering optimizes how the model interprets what it already has—not whether that material is true, complete, or safe to act on.
Invest here when: outputs are inconsistent for the same inputs, formatting breaks downstream parsers, or the model needs explicit boundaries ("never delete," "always cite the source field").
Stop here when: failures trace to missing data, wrong tools, or ungoverned side effects—no amount of rewording fixes a blank catalog.
Context engineering: the window
Context engineering treats the context window as a scarce, expensive resource you assemble deliberately. Instead of one static system prompt, you choose—per turn—what the model should see: relevant docs, service metadata, recent incident notes, prior tool results, compressed conversation history, and negative space (what to omit so signal stays high).
Typical techniques include retrieval over a knowledge base, graph-aware fetches (owners, dependencies, environments), summarization and compaction of long threads, progressive disclosure (metadata first, full instructions only when a skill activates), and hygiene on tool output (truncate logs, strip secrets, attach provenance). The goal is grounded reasoning: the model should argue from evidence your platform controls, not from weights alone.
Context engineering is where many teams discover token economics. Sending ten thousand tokens of runbooks on every "what's the status?" is a context problem, not a prompt problem. So is failing an on-call query because the agent never pulled the owning team from the catalog.
Invest here when: answers are generic, hallucination rates drop when you manually paste docs, or multi-turn sessions explode cost because nothing gets pruned or targeted.
Stop here when: the model sees the right facts but the loop still double-commits, skips verification, or bypasses policy—those are harness failures.
Harness engineering: the loop
A harness is everything that turns a chat completion into an agent: the orchestration loop (plan → call tool → observe → repeat), timeouts and retries, sandboxing, structured logging, eval hooks, cancellation, and the gates between suggestion and execution. Harness engineering is software engineering applied to unreliable components—much like you would wrap an external API you do not fully trust.
Concrete harness concerns include: which tools exist and who may invoke them; idempotency and dry-run modes; human-in-the-loop approvals for high-risk actions; comparing tool results to policy; circuit breakers when costs or error rates spike; and tracing so you can reconstruct why an agent restarted a service at 2 a.m.
Coding agents made the term visible: the model proposes edits, but the harness applies patches, runs tests, enforces directory boundaries, and stops the loop on failure. The same pattern applies to operational agents: the model proposes a runbook step; the harness checks RBAC, opens a change ticket, and records audit fields before anything touches production.
From a DevOps lens, think of the harness as what your platform already does for humans—approval gates in Jenkins or GitHub Actions, OPA on deploy, break-glass roles, change tickets—not a new category, but the same controls extended to probabilistic actors.
Invest here when: the agent can act on the world, costs scale with users, you need SOC-friendly audit trails, or "it worked in the demo" does not survive parallel users and partial outages.
Terminology note: "harness engineering" here means the generic discipline of building safe runtime control around agent actions. It is not a reference to any specific vendor or product name.
Two loops, different risk surfaces
Many teams now run two distinct loops. The inner loop is development: write, edit, test, and review code close to a repository. The outer loop is delivery: build, secure, deploy, verify, operate, and sometimes roll back across production systems.
The same model can assist both loops, but the control problem is not the same. Inner-loop failures are often caught by review and CI. Outer-loop failures can become outages, compliance incidents, or security events because they execute with credentials against live systems.
A useful mental model: speed is no longer only a productivity feature. In delivery workflows, speed is also a damage multiplier when controls are weak.
What operational agents need beyond prompts
For agents that can change running systems, four capabilities matter more than prompt polish:
- Memory — a durable map of services, owners, policies, dependencies, and past incidents.
- Context — live state for this decision: freezes, active incidents, current risk posture, and fresh scan results.
- Tools — constrained execution paths with scoped identity, least privilege, and auditable side effects.
- Verification — policy gates, approvals, and evidence that prove an action met required controls.
Missing any one of these creates familiar failure modes: confident but unsafe actions, loops that retry the wrong thing, or policy bypass through side channels.
Harness engineering in DevOps: concrete examples
In DevOps, the harness is the control plane between intent and production change—not the pipeline YAML or prompt. The same structures teams run for scripts apply when an agent proposes an action.
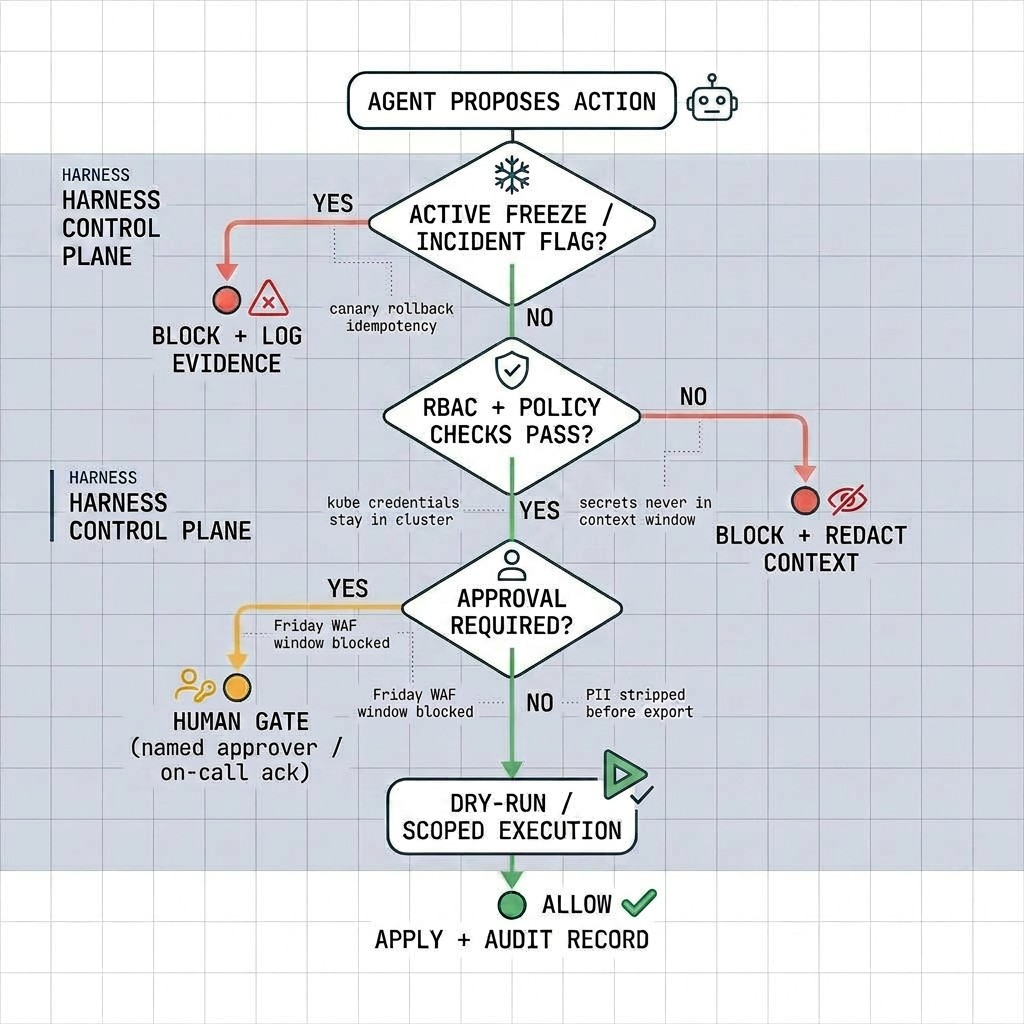
CI/CD and release gates
- Agent build promotion: When an agent proposes a promotion, the harness checks change freezes, required scorecards (coverage, CVEs), and data residency before any deploy API runs. A blocked promotion returns a structured reason (which gate failed) so the agent can retry with corrected context—not guess from a generic refusal.
- Agent canary management: If an agent-led deployment causes a failed canary, the harness triggers a rollback, enforces idempotency, logs the prior deployment ID, and blocks concurrent rollouts. That stops the classic failure mode where an agent retries rollback twice or starts a new rollout while the first is still unwinding.
Kubernetes and runtime operations
- Agent workload restarts: When an agent requests a workload restart, the harness resolves targets from the catalog, verifies RBAC, blocks if a Sev-1 incident freezes the service, runs a dry-run, and logs blast-radius. Tier-0 services may require a single-replica restart first; the audit record ties the action to the incident ID if one is open.
- Agent scale-outs: When an agent requests a scale-out, the harness caps max replicas per tier, requires on-call acknowledgment for tier-0, and routes execution through an in-cluster worker so credentials never enter model context. The agent receives replica counts and status from the worker—enough to plan the next step, not enough to exfiltrate cluster admin access.
Infrastructure and configuration
- Agent feature-flag toggles: If an agent tries to flip a flag during a checkout incident, the harness blocks the change until cleared by the commander or routes it to a human-only tool. Context may show the incident; the harness still enforces the gate so a well-worded prompt cannot bypass an active freeze.
- Agent DNS/WAF edits: When an agent proposes DNS/WAF changes, the harness enforces time windows, demands dual approval for external routes, and rolls back if synthetic checks fail within five minutes. Friday-evening WAF edits are a common policy example—the harness applies the window even when the agent cites urgency.
Secrets, data, and compliance
- Agent secret rotation: When an agent runs a secret rotation, the harness executes it in an isolated environment. The agent sees only a success or redacted error—never raw secrets in its context window. Rotation failures surface as "credential update failed: permission denied" rather than leaking vault paths or token values into the thread.
- Agent compliance boundaries: When an agent attempts cross-region changes, the harness halts execution for local co-signers and writes signed evidence of residency before calling cloud APIs. Auditors get a tamper-evident record; the agent cannot skip the co-signer by rephrasing the request.
Incident and Day 2 workflows
- Agent destructive mitigations: When an agent attempts an outage mitigation, the harness serializes actions, checks pager load windows, and updates incident records for every step. Parallel kill-and-scale proposals from the same session are queued so two destructive steps cannot race in production.
- Agent runbook automation: The harness allows agents read-only diagnostics but gates agent-proposed write actions (like cache flushes or failovers) behind approvals and verification hooks. Post-action checks (error rate, queue depth) can auto-halt the loop if the mitigation made things worse.
- Agent cost cleanup: When an agent handles cloud optimization, the harness enforces budget guardrails and hourly delete caps so looping agents cannot wipe non-prod estates. Tag-based allowlists (e.g. only resources tagged
env=dev-sandbox) narrow blast radius before any terminate API runs.
Prompt engineering phrases requests politely; context engineering surfaces the right state. Only harness engineering decides if an action runs, how it runs, and what evidence remains. Mature teams treat agents as extensions of the delivery control plane, not a chat tool with admin keys.
How they stack
Think of a single turn flowing downward: the harness decides whether a turn may run and which tools are available. Context engineering fills the window with the right slice of your estate. Prompt engineering tells the model how to use that slice (format, caution, priorities). After the model answers, the harness again—validates, executes, logs, or blocks.
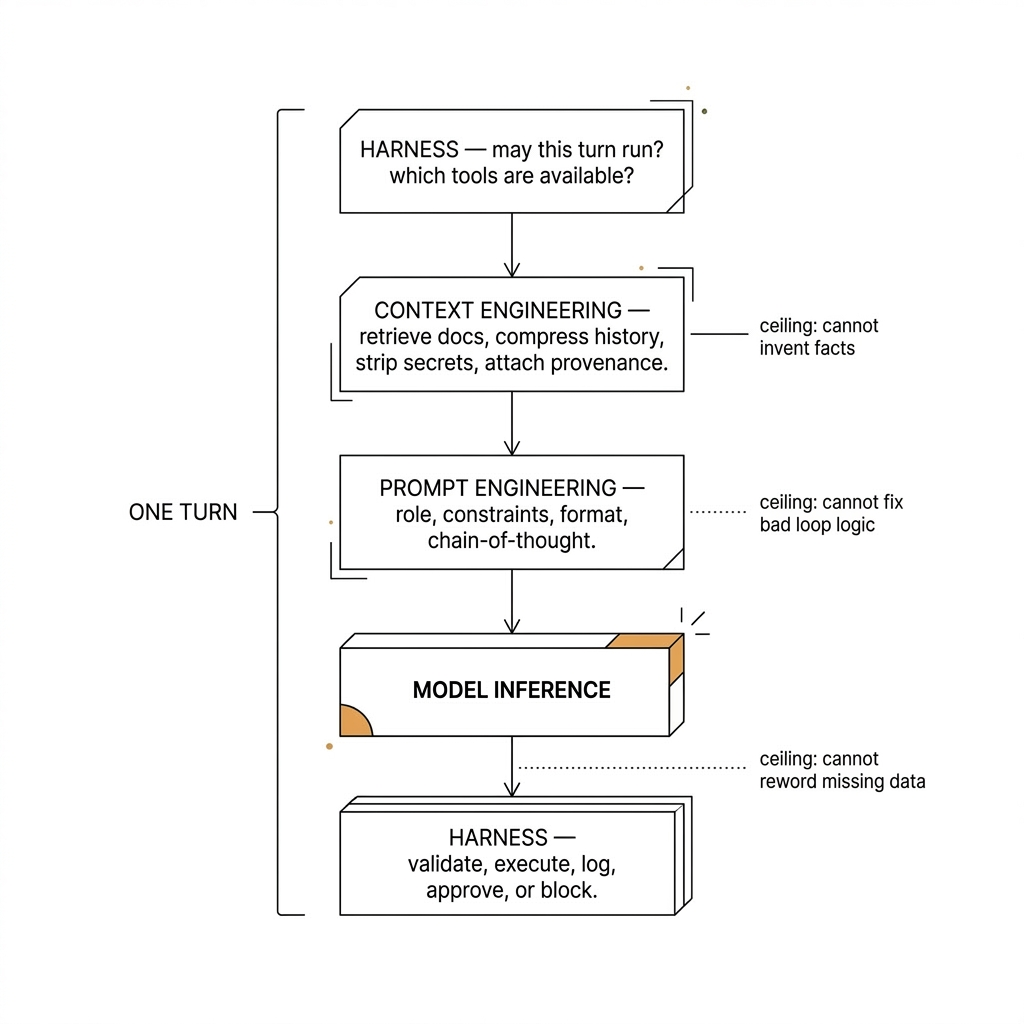
Skipping a layer shows up predictably. Prompt-only agents sound confident and know nothing. Context-rich but harness-free agents know plenty and still break prod. Harness without context becomes rigid automation with a language model lipstick—expensive and brittle.
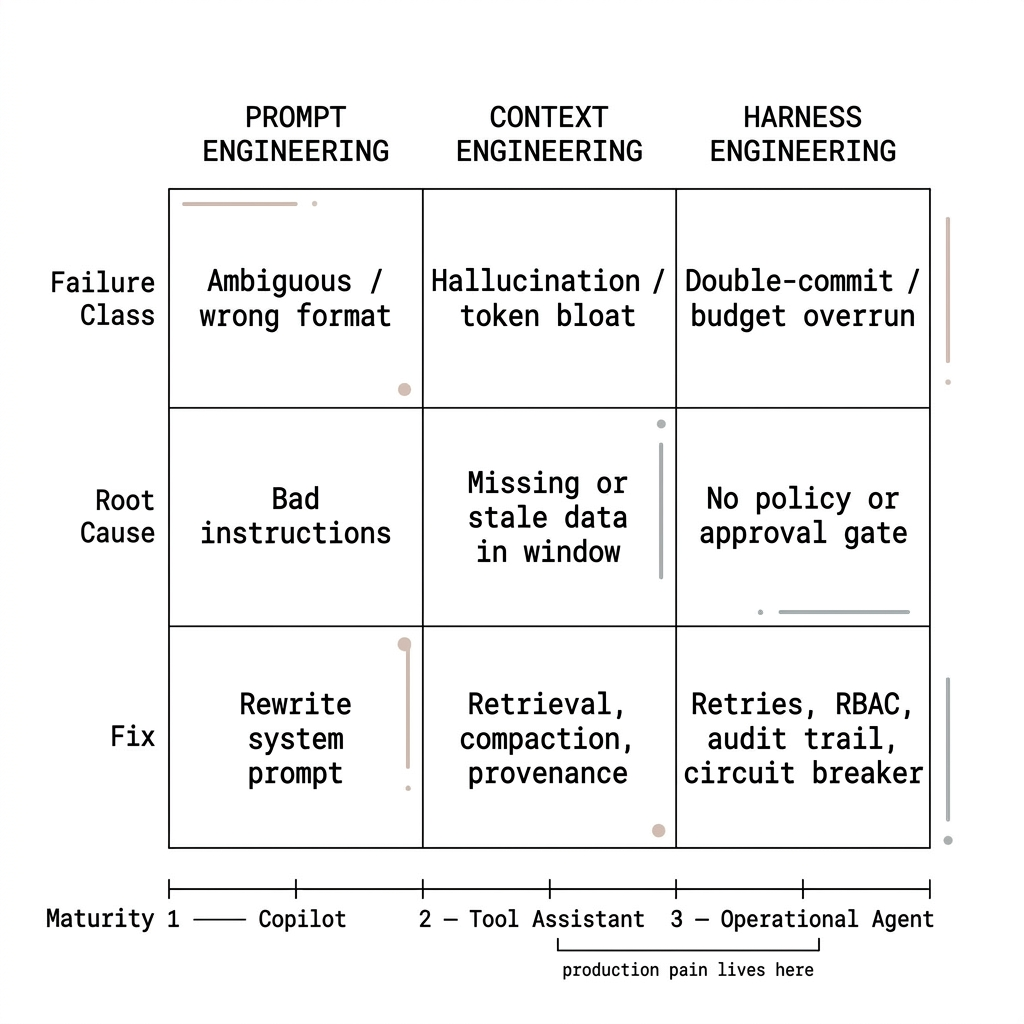
A practical maturity ladder
- Copilot / Q&A: prompt engineering plus light context (paste docs, small RAG). Harness is mostly rate limits and logging.
- Tool-using assistant: context engineering becomes mandatory—tool outputs and retrieval must be curated per turn. Harness defines the tool surface and error handling.
- Operational agent: harness engineering dominates—approvals, shared policy with humans, idempotency, and the same actions whether the user types in a console or an IDE via MCP.
Most platform teams are climbing from (1) to (3) right now. The hype cycle still markets (1) skills; production pain lives at (2) and (3).
Where a control plane fits
Day 2 Ops agents fail when context is fragmented across wikis, tickets, and tribal knowledge, and when the harness in the IDE diverges from the harness in the runbook console. A unified platform separates concerns without splitting truth: catalog and integrations feed a durable graph (context substrate); governance and approvals wrap actions the same way in every channel (harness). Prompt templates still matter—for tone, output shape, and safety copy—but they ride on top, not instead of, engineering discipline.
For token-heavy agents, pair context engineering patterns like progressive disclosure with a harness that measures cost per workflow—not just per request.
Prompt
Clear instructions for format, refusal, and tool-use etiquette.
Context
Live services, owners, dependencies, and signals—not a one-off scrape into a vector store.
Harness
Same guarded actions, audits, and approvals whether the actor is a human or an MCP client.
Closing frame
Prompt engineering is not obsolete—it is the thinnest top layer. Context engineering answers "what should the model know for this turn?" Harness engineering answers "what happens when it is wrong, and who is accountable?" Production agents need all three; the teams that win treat them as separate specialties that share one runtime, not as synonyms for typing harder into a chat box.
The practical shift underway is from model-first thinking to runtime-first thinking. Better wording still helps, but durable autonomy comes from governed execution, live context, and verification that stands up after the incident call and in front of an auditor.
Editorial—general discussion only.